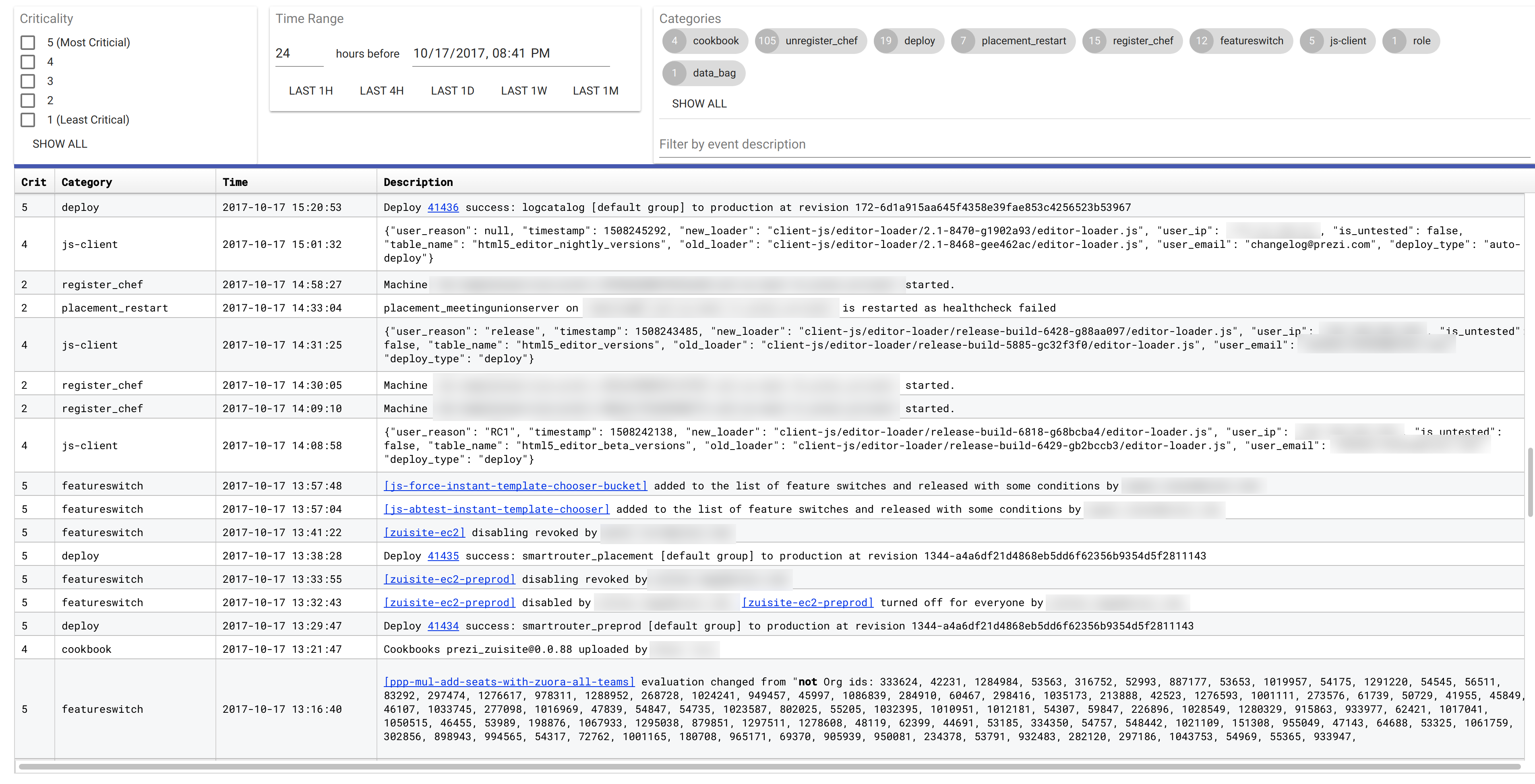
Hello!
Many Dev/Ops teams out there are using Graphite – nice tool for collecting and graphing various metrics from your software and/or hardware. It is a really nice tool and a good example of good architecture – you can check out Graphite chapter from famous AOSA book.
But it's also not a big secret that despite Graphite is great tool its scaling is really not an easy task. Until you run it on single server – everything is fine, you can easily spread it over a couple of servers but above that…
· Problem one. If you are using (default and single production ready) whisper storage, then the single option of clustering is to use normal Graphite cluster mechanism. But then, after adding or removing some nodes from cluster you need to rebalance it, using e.g. carbonate tool. It’s fine but for loaded cluster with hundreds of thousands metrics and tenths servers, it could take not hours - but days and weeks - and during rebalancing Graphite cluster will producing very funny results.
· The third problem is relay / aggregator performance problems. Graphite relays and aggregators are CPU-bound (contrary to carbon-caches, which are IO-bound) and because of python's GIL single process can't use more that one core for CPU-intensive calculations. Then you need to create some loadbalancer-based configurations with many relay processes, which doesn't make things less complex, believe me.
So, if you faced with Graphite scaling problems you have next options:
Unfortunately, it will require quite big efforts, if you have your Graphite installation up and running for a while, and have many tools and dashboards around it. Also, scaling Hbase is a the little bit harder than throwing more servers into the pool...
2. Migrate to new storage engines.
I'll explain this way little bit. Which alternative options do we have for now?
Quite mature, has some production instances running. Uses Cassandra as storage looks like the natural choice for Graphite data because of high write-load tolerance.
InfluxDB looks also like quite a natural choice for storage - it's native time series database, with built-in sharding and clustering. Dieter Plaetinck wrote this for Vimeo and run it there in production.
In my tests InfluxDB look much better as storage - it took almost exact same space as whisper, but - only for one month. It's because of InfluxDB still has no retentions with aggregations (current InfluxDB's retentions just purge old data without any aggregation) - so, if you need to make queries across big timespan (e.g. year) you need or store all data with high precision (and wasting space) or make some aggregation by own - but of course, it will hit performance quite bad. Theoretically, you can use continuous queries for aggregation on InfluxDB level, but its support not integrated to graphite-influxdb.
c) ceres. Looks like abandoned for now. I know that @dkulikovskiy made some changes in his own repo, including new roll-up mechanism – and Yandex running that on quite a big scale - but anyway, it doesn't look like a right path to go.
So, we still stick up with whisper, so, no solution for problem one yet for us, but if you only start running your Graphite – maybe it’s a good idea to run some new storage in parallel – especially if you already have some Cassandra or InfluxDB in production.
What next? What is about other problems?
In that time, my boss @vlazarenko point me on this video from Linux.conf.au 2014 – it’s only 20 minutes and worth watching. I found out from it that Booking.com uses Graphite, and uses it under quite a big load. In this video, Devdas Bhagat also mentioned that after struggling with relay scalability they developed (and what is much better – open-sourced) new and shiny C-based graphite relay, named carbon-c-relay. (Edit: first I mistakenly named it graphite-c-relay, d-oh... real name is and always was carbon-c-relay).
We started using it instantly and from that time and up to now it works very well.
Its main contributor, Fabian Groffen, also implemented aggregation and regexes in a couple of last months, so, for now, carbon-c-relay looks like complete and pretty sane alternative for python-based relay/aggregation daemons. I can find only one downside – its output is still line-based and not-pickle based but that’s completely OK for us. Edit: As @grobian mentioned (and I completely agreed with that) pickle is insecure and bloated - line protocol is better for that case.
So, third problem is solved for now.
But I was really wandered how Booking.com struggling with second scaling problem, and after following @grobian on GitHub I found out how. It seems that they rewrite most of the parts of Graphite stack in Go! And results of it's quite impressive – they’re running about 90 backend servers with more than 55TB of whisper files!
And it looks like this project implemented by only two persons - Damian “@dgryski” Gryski and @grobian. I contacted Damian, asked a couple of questions and checked how their solution works. He also said that he and @grobian will make a blog post about their stack, but they still didn't - so, I'll try to do so. J
So, how normal Graphite cluster stack looks like? I'll take part of Jamie picture to illustrate:
Did you see that 3 graphite-web servers below? They’re communicating between each over (or a single frontend to all backends), so just imagine what happens if you have 10-20-30... backend servers instead of two - and you can imagine that speed of rendering will be very low then.
Then check out Booking.com solution (they need some cool name for it, I will call it zipper-stack for brevity). Please also bear with my non-existing painting skills:
See? Graphite-web talking to the single daemon, named carbonzipper. It talks to all backends, but not over plain text based “pickle-over-HTTP” protocol, but over new “protobuf-over-HTTP” protocol - so, on backends we have a separate daemon for speaking that, named carbonserver. Also, they have special carbonapi daemon - it talks to zipper daemon also but it has some subset of Graphite functions re-implemented in Go, so, his speed is blazing fast - you can switch all your monitoring metrics (which rendering as text and not PNG) there.
So, looks good - let's deploy it.
As we are doing only evaluation we made it quick-and-dirty – just compile binaries and run it on a server, but for production you’ll need some packaging and configuration, of course. Also, it’s not a manual for Graphite installation – I assume that you have working Graphite cluster already and just want to check how-zipper stack works.
root@vagrant-ubuntu-precise-64:~# go build github.com/dgryski/carbonapi
root@vagrant-ubuntu-precise-64:~# go build github.com/dgryski/carbonzipper
root@vagrant-ubuntu-precise-64:~# go build github.com/grobian/carbonserver
root@vagrant-ubuntu-precise-64:~# ls -al ~/go/bin/carbon*
total 53552
drwxr-xr-x 2 root root 4096 Nov 28 16:32 .
drwxr-xr-x 5 root root 4096 Aug 8 13:20 ..
-rwxr-xr-x 1 root root 8796848 Oct 28 16:38 carbonapi
-rwxr-xr-x 1 root root 8526040 Oct 28 16:36 carbonserver
-rwxr-xr-x 1 root root 8515904 Oct 28 16:37 carbonzipper
Copy caronserver binary to graphite backends, and carbonzipper and carbonapi binaries to your frontend. If you do not have separate frontend - just make it - install separate server with graphite-web and install binaries there)
Go to backends first and run servers there - do not forget run it under same user as carbon-caches (e.g. using screen when testing):
~$ ./carbonserver -p=8080 -stdout=true -v=true -vv=true -w="/opt/graphite/storage/whisper"
2014/12/07 16:13:10 starting carbonserver (development build)
2014/12/07 16:13:10 reading whisper files from: /opt/graphite/storage/whisper
2014/12/07 16:13:10 set GOMAXPROCS=12
2014/12/07 16:13:10 listening on :8080
Next, run carbonzipper on the frontend. Create its config file first:
~$ cat zipper.json
{
"Backends": [
"http://10.x.y.z1:8080",
"http://10.x.y.z2:8080",
"http://10.x.y.z3:8080"
]
}
I think you got the pattern. J
Then run it in debug mode:
~$ ./carbonzipper -c="./zipper.json" -p=8080 -stdout -d=3
2014/12/07 15:58:44 starting carbonzipper (development version)
2014/12/07 15:58:44 setting GOMAXPROCS= 1
2014/12/07 15:58:44 querying servers= [http://10.x.y.z1:8080 http://10.x.y.z2:8080 http://10.x.y.z3:8080] uri= /metrics/find/?format=protobuf&query=%2A
2014/12/07 15:58:44 listening on :8080
Now you need to patch graphite-web little bit - after putting own IP to CLUSTER_SERVERS is not allowed - and that's exactly what we need to do:
--- a/webapp/graphite/storage.py
+++ b/webapp/graphite/storage.py
@@ -31,7 +31,7 @@
def __init__(self, directories=[], remote_hosts=[]):
self.directories = directories
self.remote_hosts = remote_hosts
- self.remote_stores = [ RemoteStore(host) for host in remote_hosts if not is_local_interface(host) ]
+ self.remote_stores = [ RemoteStore(host) for host in remote_hosts ]
if not (directories or remote_hosts):
raise valueError("directories and remote_hosts cannot both be empty")
Then run your frontend with CLUSTER_SERVERS = ['127.0.0.1:8080'] in local_settings.py.
Everything is prepared; you can test your frontend with normal graphs.
~$ ./carbonapi -z="http://localhost:8080" -stdout=true -p=9090 -tz="Europe/Amsterdam,3600"
2014/12/07 16:01:27 starting carbonapi (development build)
2014/12/07 16:01:27 using zipper http://localhost:8080
2014/12/07 16:01:27 using fixed timezone Europe/Amsterdam, offset 3600
2014/12/07 16:01:27 listening on port 9090
That's mostly it.
But I want to mention just one important thing. When I test my graphs with zipper-stack with curl rendering speed was quite good. But when I test my last hour graph generated by zipper-stack instance by my eyes it was looking like this:
Normal one looks like that:
Huh? Do you know what's happened there? I know, unfortunately.
As I mentioned, Graphite is a really good piece of software and use quite good engineering solutions to make thing works with quite a big load on pure Python, not even using C. And most known part of this trick is named carbon-cache. E.g. when you put metrics in graphite usually it doesn't flush to disk instantly but goes to RAM instead using carbon-cache daemon, which keeps it in memory, flushes to disk periodically, and responses results to Graphite web, merging on-disk and in-memory results.
As you can see on my diagram there're no more lines from carbon zipper to carbon-caches for zipper stack. That's right - carbonserver just reads whisper files from disk and didn't ask carbon-caches! It seems that for booking.com instances disk flushing time for every single metric is below 60 seconds, and for “1-minute retention” whisper files (which they and we are using) after each minute every file is updated and fresh. But our Graphite installation is different - we are using SAN disks and plenty of RAM instead of SSDs, so, for us it took up to 40 minutes to flush metric to disk, that’s why we have that graph depletion on “1-hour” graphs…
So, for us, it's not looks like a viable solution, alas! Or we need to implement carbon-cache interface to carbonserver in Go. But in a moment when I test zipper-stack, we were running an internal version of the hack, which shortly become PR #1010 and it works quite well, for now, so, maybe I return to it later. J
Edit: @grobian is making Go-based write daemon now - https://github.com/grobian/carbonwriter - so, maybe it could be combined with carbonserver to make similar to carbon-cache solution.
But YMMV, of course, just try zipper-stack - it looks very good and promising.